จากการอบรมเชิงปฏิบัติการ เรื่อง “รู้ทัน AI เสริมสมรรถนะบรรณารักษ์วิเคราะห์ทรัพยากรสารสนเทศ” โดย รองศาสตราจารย์ ดร.ทรงพันธ์ เจิมประยงค์ รองผู้อำนวยการสำนักงานวิทยทรัพยากร จุฬาลงกรณ์มหาวิทยาลัย นายรัฐธีร์ ปภัสสุรีย์โชติ และนายอภิวัฒน์ แก้วหะวงษ์ บรรณารักษ์ สำนักงานวิทยทรัพยากรจุฬาลงกรณ์มหาวิทยาลัย ในวันที่ 21 พฤศจิกายน 2567 ที่แบ่งเป็นภาคทฤษฎีและภาคปฏิบัติ
ในบทความเรานี้จึงแบ่งเป็นซีรี่ย์สรุปเนื้อหาที่อบรมเป็น 2 ตอน ตอนแรกว่า ด้วยทฤษฎีเกี่ยวกับบรรณารักษ์แคตตาล็อก หรือที่รู้จักกันในบรรณารักษ์งานวิเคราะห์ทรัพยากรสารสนเทศว่าต้องติดตามหรือพบเจอการเปลี่ยนแปลงในงานของตัวเองอย่างไร
-----------------------------------------------------------------------------
ก่อนอื่นขอขยายความเกี่ยวกับวงการแหล่งสารสนเทศ ที่ปัจจุบันมักมีคนเข้าใจว่า ห้องสมุด พิพิธภัณฑ์ หอจดหมายเหตุ และหอศิลป์ นั้นเป็นสิ่งที่ใกล้เคียง เป็นแหล่งเรียนรู้ เหมือน ๆ กัน สังเกตได้จากการรวมพิพิธภัณฑ์หรือหอจดหมายเหตุไว้ในหอสมุด แต่แท้จริงแล้ว แหล่งเรียนรู้เหล่านี้มีผู้จัดการทรัพยากรสารสนเทศคนละสายวิชาอาชีพ มีลักษณะการจัดการทรัพยากรแตกต่างกันออกไป แต่เมื่อบริบทสังคมต้องการเข้าถึงทรัพยากรจากทุกแหล่งในครั้งเดียวของการค้นหา การจัดระบบระเบียบข้อมูลจึงต้องปรับเปลี่ยนมาตรฐานไปเพื่อรองรับการเชื่อมโยงข้อมูลถึงกัน
ช่วงเช้า 09.00-12.00 น. ในหัวข้อ Catalogers Keep up with the changes ของ รศ.ดร. ทรงพันธ์ เจิมประยงค์ กล่าวโดยสรุปได้ว่า
งานวิเคราะห์ทรัพยากรสารสนเทศเป็นงานห้องสมุดที่หลาย ๆ สถาบันเริ่มมองเห็นถึงการนำระบบ AI (Artificial Intelligence) มาทดแทน หรือมองว่าการลงรายการบรรณานุกรมและการจัดหมวดหมู่ของทรัพยากรสารสนเทศไม่ใช่เรื่องจำเป็นอีกต่อไปในอนาคตข้างหน้า เพราะการนำข้อมูลเข้าระบบห้องสมุดอัตโนมัติแบบฉบับเต็มและใช้ระบบอัตโนมัติในการตัดคำก็ทำให้ค้นหาได้เหมือนกัน แต่แท้จริงแล้วงานวิเคราะห์ทรัพยากรฯ มีความสำคัญมากทีเดียวเพราะยิ่งมีการใช้ Generative AI ยิ่งทำให้มีการผลิตข้อมูลเกิดขึ้นใหม่ ทำให้สารสนเทศมีความกระจัดกระจายมากขึ้น ผู้คนต้องการค้นหาข้อมูลอ้างอิงจากที่ Generative AI ทำออกมาให้ จึงมีความต้องการข้อมูลต้นฉบับ อีกทั้งเพิ่มข้อมูลมรดกทางภูมิปัญญาที่จับต้องไม่ได้ เช่น การบันทึกข้อมูลภูมิปัญญาของบุคคล การวิจัยด้านชาติพันธุ์ ข้อมูลเหล่านี้รอการนำเข้า การวิเคราะห์และลงรายการจัดระเบียบอย่างเป็นระบบ เพื่อนำมาแลกเปลี่ยนกันเป็นสารสนเทศที่เชื่อถือได้ต่อไป

ข้อมูลที่บรรณารักษ์นำมาลงรายการเรียกเป็น Metadata ที่เกี่ยวข้องกับการลงรายการบรรณานุกรมของทรัพยากรสารสานเทศ และบรรณารักษ์สายวิเคราะห์ทรัพยากรฯ จำเป็นต้องต้องมีความเข้าใจและเรียนรู้ แบ่งออกเป็น 4 แนวคิดที่เกี่ยวข้องอันสำคัญ ได้แก่ 1) โครงสร้างของข้อมูล (Data Structure) 2) การลงรายละเอียดเนื้อหาของข้อมูล (Data Content : Description) 3) การแลกเปลี่ยนข้อมูล (Data Exchange) 4) มาตรฐานที่ควบคุมข้อมูล (Data Value) มีรายละเอียดดังต่อไปนี้
1. Data Structure
ปัจจุบันมีการกำหนดรูปแบบโครงสร้างข้อมูลมากมาย เช่น MARC ที่เป็นมาตรฐานการจัดการข้อมูลบรรณานุกรม มีโครงสร้างเป็น Tag Indicator และ Subfield , ชุดคำอธิบายแบบ DC Elements มี 15 Elements ใช้งานง่าย รองรับความหลากหลาย, BIBFRAME โครงสร้างที่เป็นทางเลือกที่อาจใช้แทน MARC เน้นการเชื่อมโยงข้อมูล (Linked data) , CDWA มาตรฐานสำหรับการจัดเก็บและแลกเปลี่ยนข้อมูลเกี่ยวกับงานศิลปะและสิ่งประดิษฐ์ทางวัฒนธรรม , MODS มาตรฐานสำหรับการจัดเก็บและแลกเปลี่ยนเมตาดาต้าของทรัพยากรดิจิทัล , VRA (Visual Resources Association) เพื่อการจัดเก็บและแลกเปลี่ยนข้อมูลเกี่ยวกับทรัพยากรภาพและข้อมูลทางทัศนศิลป์ , EAD มาตรฐานเมตาดาต้าสำหรับการจัดทำคำอธิบายเอกสารจดหมายเหตุ , TEI มาตรฐานสำหรับการทำเครื่องหมาย (markup) และจัดเก็บข้อมูลข้อความในรูปแบบดิจิทัล โดยเฉพาะในบริบทของเอกสารทางวิชาการ ประวัติศาสตร์ และวรรณกรรม, PREMIS (Preservation Metadata: Implementation Strategies) เป็นมาตรฐานเมตาดาต้าสำหรับการจัดการและรักษาทรัพยากรดิจิทัลในระยะยาว โดยมุ่งเน้นที่การจัดทำข้อมูลเพื่อสนับสนุนกระบวนการ Digital Preservation หรือการอนุรักษ์ทรัพยากรดิจิทัล นอกจากนี้ยังมี CIDOC CRM FRBR
2. Data Content (Description)
มาตรฐานการลงรายการทรัพยากรสารสนเทศที่เดิมทีมี AACR2 รองรับการลงรายการประเภทสิ่งพิมพ์ ต่อมามีการเพิ่มมาตรฐาน RDA เพื่อรองรับการใช้งานดิจิทัลให้สอดคล้องกัการเชื่อมโยงข้อมูล (Linked Data) อีกทั้งยังมี CCO แนวทางการบันทึกรายการวัตถุทางวัฒนธรรมและศิลปะ DACS มาตรฐานการจัดทำคำอธิบายเอกสารจดหมายเหตุ ซึ่งการรู้จักมาตรฐานดังกล่าวจะช่วยให้การอธิบายข้อมูลเป็นไปในทิศทางเดียวกันในวงการของแหล่งเรียนรู้สารสนเทศ ได้แก่ หอสมุด พิพิธภัณฑ์ หอศิลป์ หอจดหมายเหตุ
3. Data Exchange
มาตรฐานการจัดเก็บและแลกเปลี่ยนข้อมูลบรรณานุกรมในรูปแบบที่เครื่องสามารถอ่านได้ เช่น ISO2709 (MARC) , XML ภาษาที่ออกแบบมาเพื่อจัดเก็บและแลกเปลี่ยนข้อมูลที่มนุษย์และเครื่องสามารถอ่านได้ , RDF เป็นมาตรฐานสำหรับการสร้างข้อมูลที่เชื่อมโยงกันในระบบ Linked Data และ JSON เป็นรูปแบบการจัดเก็บและแลกเปลี่ยนข้อมูลที่เรียบง่าย กระชับ มีโครงสร้างที่เหมาะสำหรับการใช้งานบนเว็บไซต์และแอปพลิเคชัน
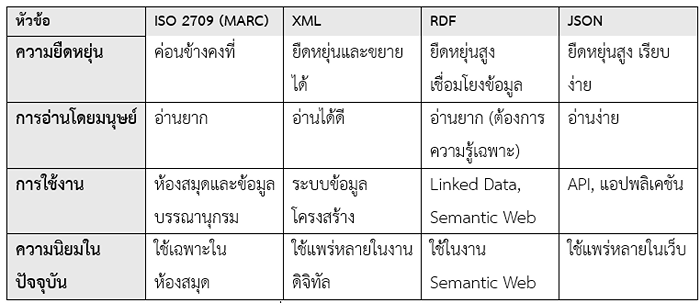
ข้อมูลเพิ่มเติม (ChatGPT4o , 25 พ.ย. 67)
4. Data Value
การบอกถึงมาตรฐานภายในเขตข้อมูล เช่น LCSH ระบบหัวเรื่องมาตรฐานที่กำหนดเป็นหัวเรื่องควบคุม ช่วยให้จัดหมวดหมู่ได้ง่ายขึ้น , AAT ศัพท์ควบคุมสำหรับจัดระเบียบข้อมูลเกี่ยวกับศิลปะ สถาปัตยกรรม และวัฒนธรรม , TGN ศัพท์ควบคุมชื่อสถานที่ทางภูมิศาสตร์ทั่วโลก , DDC ระบบการจัดหมวดหมู่หนังสือแบบให้เลขทศนิยม , LCNAF เป็นฐานข้อมูลสำหรับ ชื่อบุคคล (Personal Names) ชื่อองค์กร (Corporate Names) ชื่อเหตุการณ์ (Events) และ ชื่อชุดหนังสือ (Uniform Titles) และ ISO 639-2 เป็นมาตรฐานสากลสำหรับรหัสภาษา โดยกำหนดรหัสตัวอักษร 3 ตัวเพื่อแทนชื่อภาษา
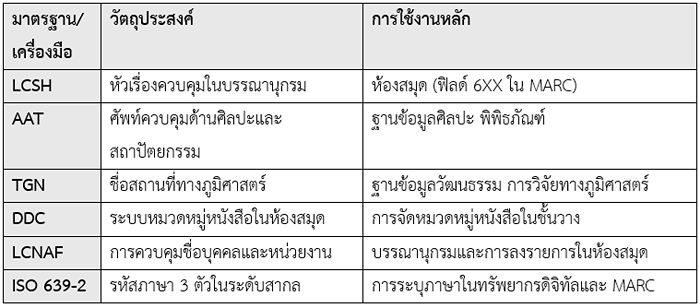
ข้อมูลเพิ่มเติม (ChatGPT4o , 25 พ.ย. 67)
บรรณารักษ์ต้องทราบเกี่ยวกับ 4 แนวคิดดังกล่าวนี้ว่ามีคนหลายสายสารสนเทศที่มีความเกี่ยวข้องกับเรื่องข้างต้นนี้อยู่ ซึ่งการออกแบบมาตรฐานเหล่านี้มาต้องวิเคราะห์อีกว่า สอดคล้องกับทรัพยากรในการจัดการของตนเองหรือไม่ มากน้อยเพียงใด เพราะเทคโนโลยีในการเชื่อมโยงข้อมูลนั้นมีมาแล้ว แต่ข้อมูลในระบบของเรานั้นพร้อมแล้วหรือยัง
ปัญหาและกลยุทธ์ของงานฝ่ายวิเคราะห์ทรัพยากรสารสนเทศ แบ่งออกเป็น 3 ส่วนสำคัญ ได้แก่ Access Discovery และ Interoperability
Access : เราสามารถรองรับต่อการหาของผู้ใช้ในปัจจุบันได้มากน้อยเพียงใด เช่น คนจำสีปกหนังสือได้ แต่ไม่มีในข้อมูลการลงรายการ การค้นคำว่า AI เจอคำว่า ปัญญาประดิษฐ์ ได้แล้วหรือยัง หอสมุดมีการทำ Authority Control แล้วหรือยัง การทำ Single Search แต่จัดระบบ Content ไม่ดี จะทำให้ผู้ใช้บริการลำบากในการหามากกว่าเดิม เหมือนหาของเล็ก ๆ ในมหาสมุทรกว้างใหญ่
Discovery : ปฏิเสธไม่ได้ว่าการค้นของ Google ถูกใจแก่ผู้ใช้งานมากกว่าทั้ง ๆ ที่เป็นระบบการค้นหาแบบเดียวกับของห้องสมุดเพียงแต่ Google เพิ่มเรื่องเรียงผลการค้นให้โดนใจผู้บริโภค (Linked Data Ranking Algorithm) ให้ความสำคัญโดยการคำนวณ Relevance อย่างเหมาะสม ไม่ได้เป็นเพียงการนับคำเท่านั้น นอกจากนี้ยังมีการเดาคำค้น AutoCompleted ที่ทำให้ผู้ใช้งานพอใจ
Interoperability : ข้อมูลในระบบต้องเชื่อมโยงกับคนอื่นได้ โดยเริ่มทดสอบจากการเชื่อมโยงในระบบขององค์กรเราเองก่อน เช่น ระหว่างหอจดหมายเหตุกับห้องสมุดในสถาบันตนเอง ระหว่างหอสมุดและพิพิธภัณฑ์ เป็นต้น แล้วค่อยทำเรื่องข้ามมหาวิทยาลัยไปจนถึงข้ามประเทศ ให้คิดเรื่อง Across Systems
ขอบเขตความรับผิดชอบ : งานวิเคราะห์ทรัพยากร ฯ อาจมองเพียงผู้ใช้บริการปัจจุบันที่ทำอย่างไรให้พวกเขาค้นหา ค้นเจอ แต่ยังไม่ได้มีใครมองถึงข้อมูลในอดีตว่าทำอย่างไร ถึงจะค้นเจอ เช่น หนังสืออนุสรณ์งานศพที่มีเนื้อหาหลากหลายอยู่ภายใน รวมถึงเชื่อมโยงกับทรัพยากรประเภทอื่นอย่างวารสาร หนังสือรุ่น เป็นต้น หรือผู้ใช้บริการในอนาคตว่าจะมีพฤติกรรมในการใช้ทรัพยากรฯ อย่างไร จะทำให้รองรับการค้นหาในอนาคตได้หรือไม่ Metadata ที่บรรณารักษ์ใส่ข้อมูลในปัจจุบันจะครอบคลุมไปถึงสิทธิในอนาคตที่ควรจะเข้าถึงได้หรือไม่
Secure Access : Metadata สำหรับชื่อคนไทยที่เปลี่ยนหลายครั้ง มีหลายวิธีเขียนเราสามารถเชื่อมโยงกับฐานข้อมูลนักวิจัยได้หรือไม่ ORCID เพื่อทำ Persistent ID authority control ROR เลข ID ของ Research organization ชื่อองค์กรเปลี่ยน , VIAF โครงการเพื่อรวบรวมและเชื่อมโยงข้อมูล authority control , ISNI มาตรฐานระหว่างประเทศสำหรับการระบุชื่อบุคคล หน่วยงาน หรือองค์กรที่มีส่วนเกี่ยวข้องกับการสร้างหรือเผยแพร่เนื้อหาทางปัญญา คิดเรื่องการรักษาความปลอดภัยของรายการวัตถุทางวัฒนธรรมว่าจะมีการลงรายการอย่างไรให้ไม่โอนเอียง อคติ ผิดเพี้ยนไปจากต้นฉบับ เช่น การใส่ข้อมูลทางวัฒนธรรมที่จับต้องไม่ได้อย่างภาษาหรือเสียงที่ไม่มีการบันทึกไว้ก่อนเมื่อนำมาบันทึกแล้วต้องแก้ไขได้หากมีการค้นพบวิจัยใหม่เกิดขึ้นว่าลักษณะที่ถูกต้องควรเป็นอย่างไร (Securing Metadata Records for Cultural Objects) เพื่อให้ข้อมูลไม่ผิดเพี้ยน การจัดการต่อข้อมูลที่เป็นอคติไม่ใช่การลด แต่ต้องเป็นการเปิดเพื่อให้เห็นวิธีคิด
ปัจจุบันข้อมูลของทรัพยากรฯที่ลงรายการเป็นลักษณะแบบ Robust Bibliographical Model คือโครงสร้างที่สื่อถึงความยืดหยุ่น ความมั่นคง และความสามารถในการรองรับการเปลี่ยนแปลงทางเทคโนโลยีและข้อมูล มีข้อมูลที่เขื่อมต่อถึง Chapter , Series ที่เกี่ยวกับหนังสือเล่มอื่น วารสารตอนอื่น หาข้อมูลที่เกี่ยวข้องเพิ่มเติมให้เข้าใจเกี่ยวกับ Linked Data
บรรณารักษ์ต้องศึกษามาตรฐานของโครงสร้างข้อมูลตลอดจนการลงรายการ การแลกเปลี่ยนข้อมูลอยู่ตลอดเวลา ดังนั้น อาจจะเริ่มจากการตั้งหลักเกณฑ์บางอย่างภายในแหล่งเรียนรู้สารสนเทศที่เกี่ยวข้องกับหอสมุดและในหอสมุดก่อน เริ่มมองหาจากคอลเลคชันบางส่วนที่อาจเกิดปัญหาต่อการสืบค้น แล้วนำมาแชร์แลกเปลี่ยนกัน เพื่อให้เกิดการใช้มาตรฐานที่เหมาะสมกับตัวเรา และในแวดวงของการลงรายการทรัพยากรสารสนเทศ แม้แต่สมาคมหอสมุดรัฐสภาอเมริกันไม่ได้ยอมรับต่อการใช้ AI ลงรายการฯ ว่าเป็น High Standard เทียบเท่าหรือทดแทนมนุษย์ เพียงแต่ให้ลองใช้ไปก่อนเท่าที่จะช่วยเหลืองานบรรณารักษ์

Categories
Hashtags